
BLACKPINK in your area
BLACKPINK — южнокорейская женская группа, работающая в жанрах K-pop и dance-pop. Группа известна яркими клипами и запоминающимися хореографиями, которые играют важную роль в их образе и популярности. Танец для BLACKPINK — это не просто часть выступлений, а один из главных способов взаимодействия с аудиторией в интернете.
В 2025 году группа выпустила клип на трек JUMP, после чего песня быстро начала набирать популярность в формате коротких видео. Особенно заметным стал рост количества танцевальных роликов в TikTok, где пользователи массово повторяли и переосмысливали хореографию из клипа, используя оригинальный звук. Таким образом, трек стал активно распространяться не только через официальный релиз, но и через пользовательский контент.
В рамках данного проекта я анализирую танцевальные видео в TikTok, созданные с использованием трека JUMP. В работе рассматривается, как меняется количество таких видео, а также их просмотры и вовлечённость. Цель анализа — понять, насколько танцевальный формат стал основным способом распространения трека в коротких видео и как именно пользователи взаимодействуют с ним.

Стиль

Палитра стиля проекта, основанная на цветовой гамме BLACKPINK
Визуализации выполнены в едином минималистичном стиле с чёрным фоном и акцентным розовым цветом #F3A2B5, который используется для ключевых элементов графиков. Типографика основана на шрифте Inter, ориентированном на интерфейсный дизайн. Второстепенные элементы оформлены в нейтральных серых оттенках, что позволяет сохранить визуальную иерархию и сфокусировать внимание на данных. Цветовая палитра основана на основных оттенках группы BLACKPINK, параметры оформления заданы программно.
Методология и ограничения
Изначально планировалось провести анализ на основе данных YouTube Shorts с использованием открытых датасетов с платформы Kaggle. Предполагалось, что такие данные позволят отследить рост танцевальных коротких видео, связанных с релизом трека JUMP, а также проанализировать их просмотры и вовлечённость.
В ходе работы выяснилось, что выборка подобных датасетов является слишком широкой и обобщённой. Данные не содержат надёжной привязки к конкретному музыкальному треку, так как информация об используемом звуке в большинстве случаев отсутствует или не указывается явно.
В связи с этим было принято решение изменить источник данных и перейти к анализу платформы TikTok, где каждый ролик жёстко привязан к конкретному звуку. Такой подход позволил сформировать более точную выборку и сосредоточиться на изучении танцевального формата как способа распространения музыкального трека в коротких видео.
Для автоматизированного сбора данных в проекте была использована платформа Apify. В качестве источника данных применялась страница звука (sound page) трека JUMP в TikTok, что позволило отобрать только те видео, которые используют один и тот же аудиотрек. Такой подход обеспечивает корректность выборки и исключает нерелевантный контент.
Ссылка на страницу звука (точнее ID, так как Apify не принимал адрес) была передана в специализированный TikTok Sound Scraper на платформе Apify, где был задан лимит на количество собираемых видео. Инструмент автоматически извлёк данные о каждом видео, включая дату публикации, количество просмотров, лайков, комментариев и репостов, а также текст описания. Полученные данные были экспортированы в формате CSV и использованы для дальнейшего анализа и визуализации с помощью библиотеки Pandas.
Для работы с данными использовались библиотеки shutil и pandas. С помощью shutil файл датасета, полученный через Apify, был скопирован в рабочую директорию среды выполнения, после чего с использованием библиотеки pandas данные были загружены в DataFrame с помощью функции pd.read_csv ().
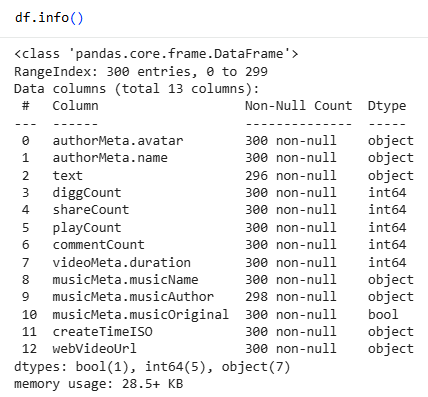
После загрузки датасета был выполнен первичный осмотр структуры данных с использованием функции df.head (), что позволило ознакомиться с содержимым первых строк таблицы и типами представленных данных. Далее с помощью функции df.info () была проанализирована структура датасета: количество строк и столбцов, типы данных, а также наличие пропущенных значений. В результате было установлено, что датасет содержит 300 записей и 13 столбцов, включая информацию об авторах видео, тексте публикаций, показателях вовлечённости, длительности видео, музыкальных метаданных и времени публикации.
Динамика количества видео с треком JUMP
Для дальнейшей обработки данных использовалась библиотека pandas. Временные метки публикации видео, содержащиеся в столбце createTimeISO, были преобразованы в формат календарной даты, при этом информация о времени публикации была отброшена. Далее были определены минимальная и максимальная даты публикации, что позволило установить временной диапазон анализируемого датасета и проверить корректность преобразования дат.
import pandas as pd import matplotlib.pyplot as plt df["date"] = pd.to_datetime(df["createTimeISO"]).dt.date df["date"].min(), df["date"].max()
Пропущенные значения в числовых метриках вовлечённости были заменены на нулевые, что обеспечивает корректность последующего анализа.
metrics = ["playCount", "diggCount", "commentCount", "shareCount"] df[metrics] = df[metrics].fillna(0)
На данном этапе все видео были сгруппированы по дням, после чего для каждой даты было подсчитано общее количество опубликованных. Полученная таблица была отсортирована в хронологическом порядке. Дополнительно к исходному временному ряду было применено 7-дневное сглаживание методом скользящей средней, что позволило уменьшить влияние резких суточных колебаний и более наглядно выявить общую тенденцию изменения активности пользователей.
videos_per_day = (
df.groupby("date")
.size()
.reset_index(name="video_count")
.sort_values("date")
)
videos_per_day["ma7"] = videos_per_day["video_count"].rolling(window=7, min_periods=1).mean()
Для визуализации и анализа динамики публикаций использовалась библиотека matplotlib. С её помощью был определён день максимальной активности путём поиска максимального значения количества опубликованных видео. Полученные значения применялись для акцентирования пикового момента на графике.
Была построена визуализация, включающая две линии: основную линию, отражающую фактическое количество танцевальных видео, опубликованных по дням, и второстепенную пунктирную линию, отображающую 7-дневную скользящую среднюю. Применение сглаживания позволило уменьшить влияние резких суточных колебаний и сделать общую тенденцию изменения пользовательской активности более наглядной.
На график была добавлена текстовая аннотация с указанием значения пика активности. Визуализация была оформлена заголовком и подписями осей.
peak_idx = videos_per_day["video_count"].idxmax() peak_date = videos_per_day.loc[peak_idx, "date"] peak_value = videos_per_day.loc[peak_idx, "video_count"]
plt.figure(figsize=(14, 6))
plt.plot(
videos_per_day["date"],
videos_per_day["ma7"],
color=COLORS["secondary"],
linewidth=2,
linestyle="--",
label="Скользящая средняя (7 дней)"
)
plt.plot(
videos_per_day["date"],
videos_per_day["video_count"],
color=COLORS["accent"],
linewidth=2.8,
label="Количество видео"
)
plt.text(
0.02, 0.92,
f"Пик активности: {peak_value} видео",
transform=plt.gca().transAxes,
fontsize=11,
color=COLORS["accent"]
)
plt.title("Динамика количества танцевальных видео с треком JUMP")
plt.xlabel("Дата публикации")
plt.ylabel("Количество видео")
plt.xticks(rotation=45)
plt.legend(frameon=False)
plt.tight_layout()
plt.show()
Линейный график динамики количества танцевальных видео с треком JUMP
Распространение трека JUMP в формате танцевальных видео носит ярко выраженный всплесковый характер и напрямую связано с моментом релиза.
Просмотры по дням
Для подготовки данных к визуализации использовалась библиотека pandas. Значения дат публикации были приведены к формату datetime, что обеспечило корректную работу с временными данными.
Для визуального акцента был определён день с максимальным количеством опубликованных видео. На основе этого значения была задана цветовая кодировка столбцов: день с наибольшей активностью был выделен основным цветом проекта, тогда как остальные дни отображались второстепенным цветом.
С использованием библиотеки matplotlib была построена горизонтальная столбчатая диаграмма, отражающая топ-10 дней по количеству танцевальных видео с треком JUMP. Для повышения информативности визуализации к каждому столбцу были добавлены числовые подписи, указывающие точное количество видео.
top10 = top10.copy()
top10["date"] = pd.to_datetime(top10["date"], errors="coerce")
top10["date_label"] = top10["date"].dt.strftime("%d.%m")
max_val = top10["video_count"].max()
bar_colors = [
COLORS["accent"] if v == max_val else COLORS["secondary"]
for v in top10["video_count"]
]
plt.figure(figsize=(12, 6))
bars = plt.barh(
top10["date_label"],
top10["video_count"],
color=bar_colors
)
for bar in bars:
w = bar.get_width()
plt.text(
w \+ max_val * 0.02,
bar.get_y() \+ bar.get_height() / 2,
f"{int(w)}",
va="center",
fontsize=10,
color=COLORS["text_primary"]
)
plt.title("Топ-10 дней по количеству танцевальных видео с треком JUMP")
plt.xlabel("Количество видео")
plt.ylabel("Дата")
plt.tight_layout()
plt.show()
Столбчатая диаграмма просмотров по дням
Наибольшее количество видео с треком JUMP публикуется в ограниченном числе дней, при этом один день явно выделяется как пик активности.
Распределение просмотров танцевальных видео
Для анализа распределения просмотров использовались библиотеки numpy и matplotlib. Из датасета были извлечены значения количества просмотров, при этом пропущенные значения были исключены. Далее к данным было применено логарифмическое преобразование по основанию 10.
Данные о просмотрах нужны, чтобы понять не только, сколько видео было создано, но и насколько эффективно они доходят до аудитории. Количество видео отражает активность пользователей, тогда как просмотры показывают реальный охват и интерес.
import numpy as np import matplotlib.pyplot as plt views = df["playCount"].dropna() views_log = np.log10(views \+ 1)
Значения по оси X на графике отражают логарифмированное количество просмотров, а не их абсолютное значение. Например, значение 5 соответствует примерно 100 тыс. просмотров, 6 — около 1 млн. просмотров. Логарифмическая шкала используется из-за сильного разброса значений просмотров в TikTok и позволяет наглядно отобразить распределение видео, не искажая картину за счёт единичных вирусных роликов.
plt.figure(figsize=(12, 6))
plt.hist(
views_log,
bins=30,
color=COLORS["secondary"],
edgecolor=None,
alpha=0.9
)
median_val = np.median(views_log)
plt.axvline(
median_val,
color=COLORS["accent"],
linewidth=2.5,
linestyle="--",
label="Медиана просмотров"
)
plt.text(
median_val,
plt.gca().get_ylim()[1] * 0.9,
"Медиана",
color=COLORS["accent"],
ha="center",
va="top",
fontsize=11
)
plt.title("Распределение просмотров танцевальных видео")
plt.xlabel("Просмотры")
plt.ylabel("Количество видео")
plt.legend(frameon=False)
plt.tight_layout()
plt.show()
Гистограмма распределения просмотров танцевальных видео
Большинство видео набирают относительно умеренное количество просмотров, в то время как небольшая часть роликов формирует пласт вирусного контента.
Просмотры и вовлечённость
Здесь рассчитывается вовлечённость видео, то есть доля активных действий пользователей по отношению к количеству просмотров. Для этого суммируются лайки, комментарии и репосты и делятся на общее число просмотров. Такой показатель позволяет сравнивать видео между собой независимо от их масштаба.
Далее из данных исключаются видео с нулевыми просмотрами или нулевой вовлечённостью, чтобы избежать искажений и некорректных значений при анализе. После этого количество просмотров приводится к логарифмической шкале, что позволяет корректно сравнивать видео с сильно различающимся охватом и использовать эти данные для последующей визуализации взаимосвязи просмотров и вовлечённости.
import numpy as np
import matplotlib.pyplot as plt
df["engagement_rate"] = (
df["diggCount"] \+
df["commentCount"] \+
df["shareCount"]
) / df["playCount"]
scatter_df = df[
(df["playCount"] > 0) &
(df["engagement_rate"] > 0)
].copy()
scatter_df["views_log"] = np.log10(scatter_df["playCount"])
Диаграмма показывает, что рост просмотров не всегда сопровождается ростом вовлечённости. Для части видео с высоким числом просмотров уровень взаимодействия пользователей оказывается ниже медианного, что указывает на различие между вирусным охватом и активным участием аудитории.
plt.figure(figsize=(12, 6))
plt.scatter(
scatter_df["views_log"],
scatter_df["engagement_rate"],
color=COLORS["secondary"],
alpha=0.35,
s=25
)
median_views = scatter_df["views_log"].median()
median_engagement = scatter_df["engagement_rate"].median()
plt.axvline(
median_views,
color=COLORS["grid"],
linestyle="--",
linewidth=1
)
plt.axhline(
median_engagement,
color=COLORS["grid"],
linestyle="--",
linewidth=1
)
plt.scatter(
median_views,
median_engagement,
color=COLORS["accent"],
s=80,
zorder=5
)
plt.text(
0.02, 0.95,
"Точка медиан\n(просмотры × вовлечённость)",
transform=plt.gca().transAxes,
fontsize=11,
color=COLORS["text_primary"]
)
plt.title("Связь просмотров и вовлечённости на видео")
plt.xlabel("Просмотры")
plt.ylabel("Вовлечённость")
plt.tight_layout()
plt.show()
Точечная диаграмма связи просмотров и вовлечённости на видео
Вовлечённость пользователей
С использованием библиотеки pandas время публикации видео было приведено к формату календарного дня путём округления временных меток до начала суток. После этого для каждой даты были суммированы показатели вовлечённости — лайки, комментарии и репосты. Полученный результат был отсортирован в хронологическом порядке и использован для анализа изменения общей вовлечённости пользователей.
df["date"] = pd.to_datetime(df["createTimeISO"]).dt.floor("D")
engagement_daily = (
df.groupby("date")[["diggCount", "commentCount", "shareCount"]]
.sum()
.reset_index()
.sort_values("date")
)
Лайки — основной объём вовлечённости
Лайки формируют основной объём пользовательской реакции и отражают общий уровень популярности контента.
plt.figure(figsize=(14, 6))
plt.fill_between(
engagement_daily["date"],
engagement_daily["diggCount"],
color=COLORS["accent"],
alpha=0.85
)
plt.title("Лайки на видео")
plt.xlabel("Дата публикации")
plt.ylabel("Количество лайков")
plt.tight_layout()
plt.show()
Сложенный график динамики лайков на видео
Комментарии и репосты — активное взаимодействие
Комментарии и репосты отражают более осознанное участие аудитории и позволяют оценить глубину вовлечённости.
plt.figure(figsize=(14, 6))
plt.fill_between(
engagement_daily["date"],
engagement_daily["commentCount"],
color=COLORS["secondary"],
alpha=0.7,
label="Комментарии"
)
plt.fill_between(
engagement_daily["date"],
engagement_daily["shareCount"],
color=COLORS["grid"],
alpha=0.9,
label="Репосты"
)
plt.title("Комментарии и репосты")
plt.xlabel("Дата публикации")
plt.ylabel("Количество взаимодействий")
plt.legend(frameon=False)
plt.tight_layout()
plt.show()
Сложенный график динамики комментариев и репостов
Структура вовлечённости
Несмотря на доминирование лайков в абсолютных значениях, относительная доля комментариев и репостов меняется во времени, что указывает на различие форм пользовательского участия.
engagement_daily["total"] = (
engagement_daily["diggCount"] \+
engagement_daily["commentCount"] \+
engagement_daily["shareCount"]
)
likes_pct = engagement_daily["diggCount"] / engagement_daily["total"]
comments_pct = engagement_daily["commentCount"] / engagement_daily["total"]
shares_pct = engagement_daily["shareCount"] / engagement_daily["total"]
plt.figure(figsize=(14, 6))
plt.stackplot(
engagement_daily["date"],
likes_pct,
comments_pct,
shares_pct,
labels=["Лайки", "Комментарии", "Репосты"],
colors=[COLORS["accent"], COLORS["secondary"], COLORS["grid"]],
alpha=0.9
)
plt.title("Структура вовлечённости: доли типов взаимодействий")
plt.xlabel("Дата публикации")
plt.ylabel("Доля от общей вовлечённости")
plt.legend(frameon=False, loc="upper left")
plt.tight_layout()
plt.show()
Сложенная структура вовлечённости долей типов взаимодействий
Заключение
В рамках проекта были проанализированы танцевальные видео в TikTok с использованием трека JUMP, а также динамика их публикации и вовлечённости. Анализ показал, что основной формой взаимодействия аудитории являются лайки, в то время как комментарии и репосты составляют меньшую, но показательно активную часть реакции пользователей. В периоды пикового интереса возрастает не только общее количество видео, но и уровень вовлечённости. Это подтверждает, что танцевальный формат стал ключевым способом распространения трека в коротких видео и важным инструментом пользовательского взаимодействия с музыкой.
Описание применения генеративной модели
В проекте использовались инструменты генеративного ИИ и графического редактирования.
ChatGPT применялся для помощи в работе с кодом и текстовом оформлении исследования.
Adobe Photoshop 2024 использовался для финальной визуальной доработки материалов, включая оформление изображений, обложек и графических элементов проекта.
Описание используемых статистических методов
- Описательная статистика. Использовалась для первичного анализа данных, включая подсчёт количества видео, просмотров и показателей вовлечённости.
- Агрегация данных по времени. Данные группировались по датам публикации для анализа динамики количества видео и пользовательской активности во времени.
- Медиана как мера центральной тенденции. Применялась для оценки типичного уровня просмотров и вовлечённости.
- Логарифмическое преобразование данных. Использовалось для визуализации распределения просмотров с большим разбросом значений и уменьшения влияния экстремальных значений.
- Расчёт показателя вовлечённости. Вовлечённость вычислялась как отношение суммы лайков, комментариев и репостов к числу просмотров видео.
- Анализ взаимосвязей между показателями. Для изучения связи между просмотрами и вовлечённостью.
- Нормализация данных. Использовалась для анализа структуры вовлечённости путём представления лайков, комментариев и репостов в виде долей от общей активности.


