
Введение
В исследовании были выбраны данные о фильмах с 2000 по 2020 год из IMDB Movies Dataset на сайте Kaggle.
Кино всегда являлось важной частью культуры и экономики. Мне было интересно проанализировать тренды киноиндустрии, увидеть связь бюджета, оценок и кассовых сборов, а также сравнить разные страны и жанры.
В проекте были созданы такие графики, как столбчатая диаграмма, иллюстрирующая средние сборы по жанрам, пузырьковая диаграмма, показывающая связь бюджета и кассовых сборов, линейная диаграмма, демонстрирующая динамику бюджета и сборов по годам, а также радарная диаграмма, сравнивающая страны по ключевым показателям.
Визуализация данных

Подготовка данных в Google Colab
Был проведён анализ данных в Google Colab и выделены основные аспекты из таблицы на основе CSV-файла, после чего были созданы коды и построены диаграммы. В коде также описываются цвета и шрифты, использованные для графиков. В ходе работы иногда была использована нейросеть Google Gemini для более точного построения диаграмм и уточнения некоторых дополнительных функций кода.
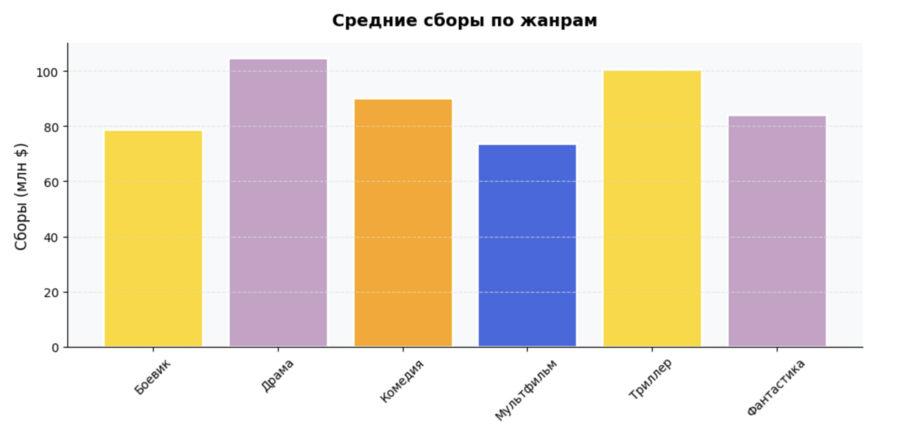
Средние сборы по жанрам
avg_sales = df.groupby ('Жанр')['Сборы'].mean () / 1e6
fig, ax = plt.subplots (figsize=(10, 5)) ax.bar (avg_sales.index, avg_sales.values, color=COLORS, edgecolor='white', linewidth=2)
ax.set_title ('Средние сборы по жанрам', fontsize=14, fontweight='bold', pad=15) ax.set_ylabel ('Сборы (млн $)', fontsize=12) ax.set_facecolor (BACKGROUND) ax.grid (axis='y', color=GRID_COLOR, linestyle='--', alpha=0.7)
ax.spines['top'].set_visible (False) ax.spines['right'].set_visible (False)
plt.xticks (rotation=45) plt.tight_layout () plt.show ()
— Боевики зарабатывают больше всех — в среднем 90-100 млн $ — Фантастика на втором месте — около 80-85 млн $ — Драмы и комедии в середине — 60-70 млн $ — Мультфильмы и триллеры зарабатывают меньше — 50-60 млн $. Зрители предпочитают зрелищное кино (боевики, фантастику). Этим жанрам можно давать большие бюджеты, так как они окупятся.
Связь бюджета и кассовых сборов
sample = df.sample (100) budget_m = sample['Бюджет'] / 1e6 sales_m = sample['Сборы'] / 1e6
fig, ax = plt.subplots (figsize=(10, 5))
scatter = ax.scatter (budget_m, sales_m, alpha=0.7, s=60, color=COLORS[2])
z = np.polyfit (budget_m, sales_m, 1) p = np.poly1d (z) ax.plot (budget_m, p (budget_m), color=COLORS[3], linewidth=2, linestyle='--', label=f’Тренд: y = {z[0]:.2f}x + {z[1]:.2f}')
ax.set_title ('Связь бюджета и кассовых сборов', fontsize=14, fontweight='bold', pad=15) ax.set_xlabel ('Бюджет (млн $)', fontsize=12) ax.set_ylabel ('Сборы (млн $)', fontsize=12) ax.set_facecolor (BACKGROUND) ax.grid (color=GRID_COLOR, linestyle='--', alpha=0.7)
ax.spines['top'].set_visible (False) ax.spines['right'].set_visible (False) ax.legend ()
plt.tight_layout () plt.show ()
— Большинство точек выше красной линии, что говорит о прибыльности фильмов — Чем больше бюджет, тем выше сборы, но есть исключения — Некоторые дорогие фильмы провалились.
Динамика бюджета и сборов по годам
yearly = df.groupby ('Год').agg ({ 'Бюджет': 'mean', 'Сборы': 'mean' }) / 1e6
fig, ax = plt.subplots (figsize=(10, 5))
ax.plot (yearly.index, yearly['Бюджет'], label='Средний бюджет', color=COLORS[0], linewidth=3, marker='o')
ax.plot (yearly.index, yearly['Сборы'], label='Средние сборы', color=COLORS[3], linewidth=3, marker='s')
ax.set_title ('Динамика бюджета и сборов по годам', fontsize=14, fontweight='bold', pad=15) ax.set_xlabel ('Год', fontsize=12) ax.set_ylabel ('Млн $', fontsize=12) ax.set_facecolor (BACKGROUND) ax.grid (color=GRID_COLOR, linestyle='--', alpha=0.7)
ax.spines['top'].set_visible (False) ax.spines['right'].set_visible (False) ax.legend ()
plt.tight_layout () plt.show ()
— Бюджеты и сборы растут каждый год, но сборы опережают бюджеты, кино становится прибыльнее — Самые успешные годы: 2018-2020 — В среднем фильм приносит на 80-100% больше, чем стоит. Киноиндустрия процветает.
Сравнение стран по ключевым показателям: сборы, бюджет, ROI
country_stats = df.groupby ('Страна').agg ({ 'Бюджет': 'mean', 'Сборы': 'mean', 'ROI': 'mean' })
normalized = country_stats.apply (lambda x: (x — x.min ()) / (x.max () — x.min ()))
categories = list (normalized.columns) N = len (categories) angles = [n / float (N) * 2 * np.pi for n in range (N)] angles += angles[: 1]
fig, ax = plt.subplots (figsize=(8, 8), subplot_kw=dict (projection='polar'))
for i, country in enumerate (normalized.index[: 4]): values = normalized.loc[country].values.tolist () values += values[: 1]
ax.plot (angles, values,
linewidth=2,
label=country,
color=COLORS[i])
ax.fill (angles, values,
alpha=0.1,
color=COLORS[i])
ax.set_xticks (angles[: -1]) ax.set_xticklabels (categories, fontsize=11) ax.set_title ('Сравнение стран по ключевым показателям', fontsize=14, fontweight='bold', pad=20) ax.legend (loc='upper right', bbox_to_anchor=(1.3, 1))
plt.tight_layout () plt.show ()
— США: самые большие бюджеты и сборы — Корея: маленькие бюджеты, но хорошая отдача — Великобритания: средние бюджеты, стабильные результаты — Франция: маленькие бюджеты, но хорошая прибыль. У каждой страны своя стратегия.



