О задаче
В рамках курса нужно было выбрать данные, которые интересны и с помощью Pandas провести анализ данных и визуализацию. В своей работе я выбрала анализировать цены на автомобили
Данные и источник
1000 наблюдений об автомобилях Цена: Price_USD Числовые признаки: пробег, объём двигателя, мощность, расход, места Категории: бренд, топливо, коробка, тип владельца Фичи: возраст авто (Car_Age), лог-цена (Price_log) Kaggle — открытая база даных Использован файл «car_price_dataset_medium 2.csv» (n=1 000). Поля описывают характеристики автомобиля и цену (Price_USD).
Почему тема интересна
• Можно проверить, какие факторы связаны с ценой (возраст, пробег, мощность, владелец). • Датасет удобен для демонстрации графиков и базовых статистических методов.
Инженерия признаков и выбросы
Добавлены признаки: Car_Age = 2026 − Model_Year и Price_log = log (Price_USD). Выбросы по цене оценены правилом Тьюки (IQR): [-55,556; 172,676] USD, потенциальных выбросов: 0. Ключевые цифры по Price_USD: min 3,028, max 119,612, среднее 59,217, медиана 56,807 (USD).
Стиль инфографики
Единый тёмный фон + 1 акцентный цвет Сетка и подписи приглушены (меньше шума) В каждом графике — пояснение «как читать» Идея: визуализация как мини-урок, не просто картинка
Статистика
Описательная статистика (mean/median/std, квартили) IQR-правило (Tukey) для выбросов Pearson корреляции Kruskal–Wallis (3+ групп) Mann–Whitney U / Welch t-test (2 группы) OLS: log (Price) ~ признаки + категории
Пакет графиков
- Гистограмма цены + mean/median
- Boxplot цены по Owner_Type
- Средняя цена по брендам + 95% CI
- Scatter пробег vs log (цены) + регрессия
- Heatmap корреляций
График 1 — распределение цен
Гистограмма показывает, сколько автомобилей попадает в каждый ценовой диапазон. Среднее (пунктир) и медиана (сплошная) помогают понять «типичную» цену. Если среднее намного выше медианы -> правый «хвост» и редкие дорогие авто. Вывод: в этом датасете mean и median близки → сильной асимметрии нет.
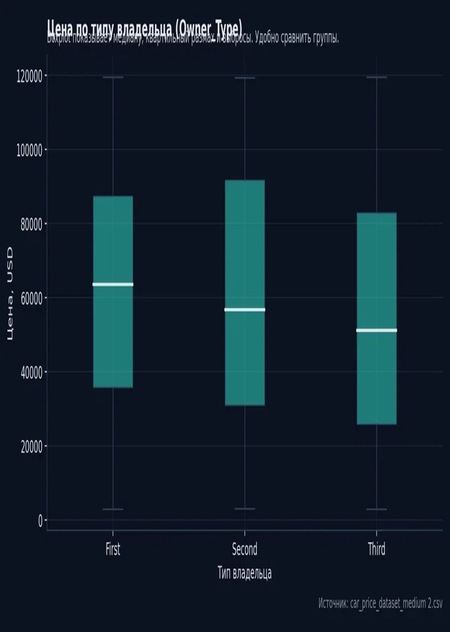
График 2 — цена по типу
Boxplot удобен для сравнения групп: центр — медиана, коробка — Q1.Q3. Группы можно ранжировать по медиане (у нас: First выше Third). Проверка гипотезы: Kruskal–Wallis даёт p≈0.0125 -> различия между группами значимы. Практический смысл: «число владельцев» связано с ценой — как минимум в этих данных.
График 3 — бренды: средняя цена и неопределённость
Среднее без «усов» часто обманчиво: у брендов разный размер выборки и разброс. 95% CI ≈ mean ± 1.96·SE, где SE = std/√n. Если CI сильно пересекаются, различия средних могут быть неубедительными. Подход помогает честно показывать неопределённость, а не только «топ-10».
График 4 — цена и пробег
Каждая точка — один автомобиль (пробег -> лог-цена). Логарифм цены уменьшает влияние «дорогого хвоста» и стабилизирует разброс. Оценка связи: r≈0.044, p≈0.163 -> в этих данных связь крайне слабая. Вывод: цена почти не объясняется пробегом — вероятно, нужны дополнительные факторы.
График 5 — корреляции признаков
Pearson r показывает только линейную связь (r≈0 не исключает нелинейность). В этом датасете все корреляции малы: максимум около |r|≈0.08. Значит, простые линейные зависимости между числовыми признаками слабые.
Дальше: пробовать нелинейные модели/ и добавить недостающие факторы.
Итоги и что можно улучшить
Распределение цен широкое, без ярко выраженного перекоса. Цена отличается по Owner_Type (p<0.05). Пробег и числовые признаки слабо связаны с ценой (низкие r). Бренды отличаются по средним, но важно показывать CI.
Ограничения и next steps
В данных могут отсутствовать ключевые факторы: состояние, комплектация, аварии, регион. Проверить нелинейности (сплайны/деревья), взаимодействия (Brand×Age). Сделать модель: train/test, MAE/RMSE, важность признаков. Добавить интерактив (Plotly) или сделать дашборд.



