Анализ зрительской активности: фильмы и сериалы
Современное медиапространство предлагает огромное количество контента: фильмы, сериалы, шоу разных жанров и стран производства. Аудитории интересно понять, какой тип контента пользуется наибольшей популярностью и какие факторы влияют на выбор зрителей. Анализ данных помогает выявить закономерности и наглядно продемонстрировать предпочтения зрителей.
Задача
Проанализировать данные о фильмах и сериалах, чтобы ответить на ключевые вопросы.
Цель
Сформировать визуальные и количественные выводы о зрительских предпочтениях, выявить закономерности в популярности контента и показать, какие факторы сильнее всего влияют на то, что выбирают зрители.
Вопросы
- Как менялось количество фильмов и сериалов с течением времени?
- Что в среднем смотрят чаще — фильмы или сериалы?
- Отличаются ли популярные жанры у фильмов и сериалов?
- Какие факторы сильнее всего влияют на то, что смотрят чаще: формат, жанр или год выхода?
Публичные данные для анализа фильмов и сериалов
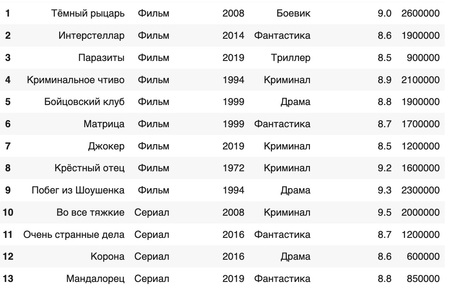
Структура датасета:
- Название
- Формат контента: «Фильм» или «Сериал»
- Год выпуска
- Жанр
- Рейтинг IMDB
- Голоса
Методы анализа
- Обработка и очистка данных
- Группировка данных
- Статистический анализ
- Визуализация данных
- Выводы и интерпретация
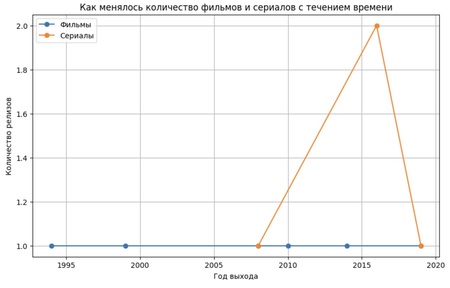
Как менялось количество фильмов и сериалов с течением времени? Кино держит ровную линию, а сериалы — формат с волнами интереса и ростом в более поздний период.
import pandas as pd import matplotlib.pyplot as plt
df = pd.read_csv («moviesdataset.ssv», sep=»;»)
print (df.head ()) print (df.columns)
df[«type»] = df[«type»].str.strip ().str.lower ()
print (df[«type»].unique ())
df = df[[«release_year», «type»]]
movies = df[df[«type»] == «movie»] tvshows = df[df[«type»] == «tv show»]
movies_by_year = movies.groupby («release_year»).size () tv_by_year = tvshows.groupby («release_year»).size ()
movies_by_year = movies_by_year.sort_index () tv_by_year = tv_by_year.sort_index ()
plt.figure (figsize=(10, 6))
movies_by_year.index,
movies_by_year.values,
marker="o»,
label="Фильмы»
) plt.plot ( tv_by_year.index, tv_by_year.values, marker="o», label="Сериалы» ) plt.title («Как менялось количество фильмов и сериалов с течением времени») plt.xlabel («Год выхода») plt.ylabel («Количество релизов») plt.legend () plt.grid (True)
plt.show ()
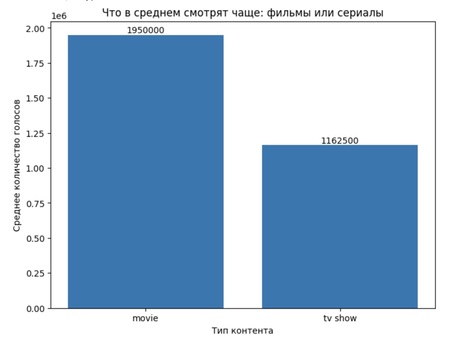
Что в среднем смотрят чаще — фильмы или сериалы? 1. В среднем фильмы получают больше голосов, чем сериалы. 2. Это подтверждает, что формат контента сильно влияет на его популярность.
import pandas as pd import matplotlib.pyplot as plt
df = pd.read_csv («moviesdataset.ssv», sep=»;»)
print (df.head ()) print (df.columns)
df[«type»] = df[«type»].str.strip ().str.lower ()
print (df[«type»].unique ())
df = df[[«type», «votes»]]
df = df.dropna (subset=[«votes»])
df[«votes»] = pd.to_numeric (df[«votes»], errors="coerce») df = df.dropna (subset=[«votes»])
avg_votes = ( df.groupby («type»)[«votes»] .mean () ) print (avg_votes)
plt.figure (figsize=(8, 6))
plt.bar ( avg_votes.index, avg_votes.values ) plt.title («Что в среднем смотрят чаще: фильмы или сериалы») plt.xlabel («Тип контента») plt.ylabel («Среднее количество голосов»)
for i, value in enumerate (avg_votes.values): plt.text (i, value, int (value), ha="center», va="bottom»)
plt.show ()
Отличаются ли популярные жанры у фильмов и сериалов? 1. У фильмов наблюдается более равномерное распределение популярности жанров, при этом sci-fi лидирует. 2.У сериалов доминируют sci-fi и drama, остальные жанры менее популярны. 3.Предпочтения аудитории различаются по формату: жанры фильмов и сериалов не совпадают полностью.
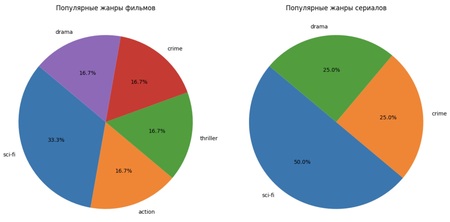
import pandas as pd import matplotlib.pyplot as plt
df = pd.read_csv («moviesdataset.ssv», sep=»;»)
df[«type»] = df[«type»].str.strip ().str.lower () df[«genre»] = df[«genre»].str.strip ().str.lower ()
print (df[«type»].unique ()) print (df[«genre»].unique ())
movies = df[df[«type»] == «movie»] tvshows = df[df[«type»] == «tv show»]
movies_genre_counts = movies[«genre»].value_counts () tv_genre_counts = tvshows[«genre»].value_counts ()
plt.figure (figsize=(12, 6))
plt.subplot (1, 2, 1) plt.pie ( movies_genre_counts, labels=movies_genre_counts.index, autopct="%1.1f%%», startangle=140 ) plt.title («Популярные жанры фильмов»)
plt.subplot (1, 2, 2) plt.pie ( tv_genre_counts, labels=tv_genre_counts.index, autopct="%1.1f%%», startangle=140 ) plt.title («Популярные жанры сериалов»)
plt.tight_layout () plt.show ()
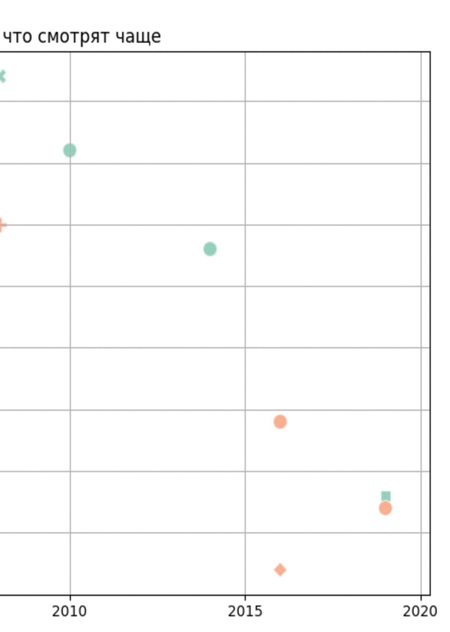
Какие факторы сильнее всего влияют на то, что смотрят чаще: формат, жанр или год выхода? 1. Популярность контента зависит от формата (фильмы набирают больше голосов, чем сериалы). 2. Жанр также влияет: sci-fi и action чаще собирают больше голосов. 3. Год выпуска играет роль: новые и недавние релизы получают меньше голосов из-за меньшего времени на накопление аудитории.
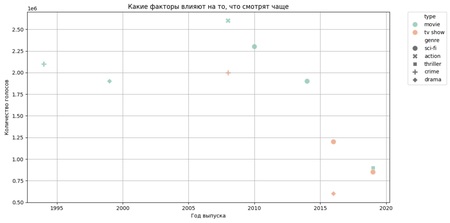
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
df = pd.read_csv («moviesdataset.ssv», sep=»;»)
df[«type»] = df[«type»].str.strip ().str.lower () df[«genre»] = df[«genre»].str.strip ().str.lower () df = df.dropna (subset=[«votes», «release_year», «type», «genre»])
df[«votes»] = pd.to_numeric (df[«votes»], errors="coerce») df[«release_year»] = pd.to_numeric (df[«release_year»], errors="coerce») df = df.dropna (subset=[«votes», «release_year»])
plt.figure (figsize=(12, 6)) sns.scatterplot ( data=df, x="release_year», y="votes», hue="type», style="genre», s=100, ) plt.title («Какие факторы влияют на то, что смотрят чаще») plt.xlabel («Год выпуска») plt.ylabel («Количество голосов») plt.legend (bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.) plt.grid (True) plt.tight_layout () plt.show ()
Ключевые выводы
- Анализ показал, что количество выпускаемых сериалов растёт постепенно, однако фильмы по-прежнему остаются доминирующим форматом, несмотря на небольшие колебания во времени. Это говорит о стабильной популярности киноиндустрии и привычке зрителей выбирать фильмы.
- Респонденты чаще выбирают фильмы. Сериалы смотрят реже, вероятно, из-за их длительности и необходимости регулярного просмотра, тогда как фильмы позволяют получить завершённый сюжет за один сеанс.
- Исследование выявило, что популярные жанры отличаются. Для фильмов лидируют, тогда как сериалы чаще выбирают в жанрах. Это отражает различия в целях и ожиданиях зрителей от форматов: фильм — быстрое развлечение, сериал — длительное вовлечение.
- На предпочтения зрителей сильнее всего влияет формат: фильмы выбирают чаще из-за удобства и компактности. Жанр также важен, но менее критичен, а год выхода оказывает минимальное влияние на частоту просмотра.
Описание применения генеративной модели
В ходе исследования генеративная модель использовалась для:
- Формулировки исследовательских вопросов по теме «Фильмы и сериалы»;
- Редактуры и уточнения текстовых формулировок выводов и заключений, а также описаний к графикам.
Использованная модель: GPT-5.2 Thinking (ChatGPT, OpenAI) Ссылка: https://chat.openai.com
Заключение
Проведённый анализ показал, что фильмы остаются более популярным видом досуга по сравнению с сериалами. Их преимущество заключается в завершённости сюжета за короткое время, что делает их удобными для широкой аудитории. Сериалы, несмотря на рост количества выпускаемых проектов и разнообразие жанров, привлекают меньше зрителей, скорее всего, из-за значительных временных затрат.
Ссылка на IPYNB



