Рубрикатор
1. Вводная часть 2. Этапы работы 3. Итоговые графики 4. Вывод 5. Описание применения генеративной модели
Вводная часть
Для анализа я выбрала данные из набора «Healthcare Survey» с сайта kaggle.com. Этот набор данных включает информацию о различных аспектах здравоохранения, таких как доступность медицинских услуг, удовлетворенность пациентов, а также демографические данные респондентов. Мне было интересно проанализировать эти данные, так как тема здоровья является одной из самых важных и актуальных тем. Здоровье — ключевой фактор качества жизни, и с помощью анализа можно выявить важные взаимосвязи: например, как уровень дохода или образования влияет на состояние здоровья.
Я решила сделать разные виды графиков, которые помогли наглядно представить конкретные данные, выбранные мной для анализа. Распределение общего состояния здоровья — гистограмма. Связь уровня образования и здоровья — столбчатая диаграмма. Связь физической активности и здоровья — диаграмма рассеяния. Зависимость уровня дохода от возраста — линейный график. Распределение медицинского образования — круговая диаграмма.
Этапы работы
Я решила стилизовать графики в оттенках синего. Этот цвет является успокаивающим и подходит для визуализации данных, связанных с вопросом здоровья.
Для начала нужно было подготовить данные и обработать пропущенные значения.
import pandas as pd df = pd.read_csv ('health_dataset.csv') df.head ()
missing_values = df.isnull ().sum () missing_values[missing_values > 0]
В данных есть пропущенные значения только в колонке Smoked — 110 значений. Заменим их модой.
df[«Smoked»] = df[«Smoked»].fillna (df[«Smoked»].mode ()[0])
Проверим, что пропусков больше нет
df.isnull ().sum ().sum ()
Данные готовы к визуализации
import matplotlib.pyplot as plt import seaborn as sns
Настроим стиль визуализации sns.set_style («whitegrid») plt.figure (figsize=(8, 5))
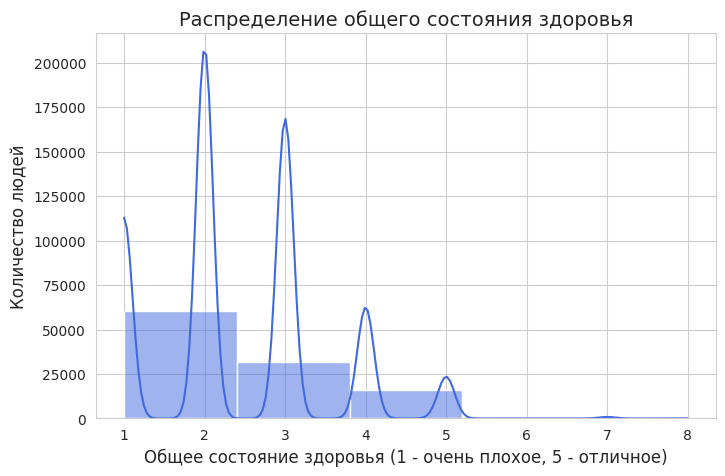
Первая визуализация показывает распределение общего состояния здоровья людей
sns.histplot (df[«Gen_health_state»], bins=5, kde=True, color="royalblue»)
plt.title («Распределение общего состояния здоровья», fontsize=14) plt.xlabel («Общее состояние здоровья (1 — очень плохое, 5 — отличное)», fontsize=12) plt.ylabel («Количество людей», fontsize=12)
plt.show ()
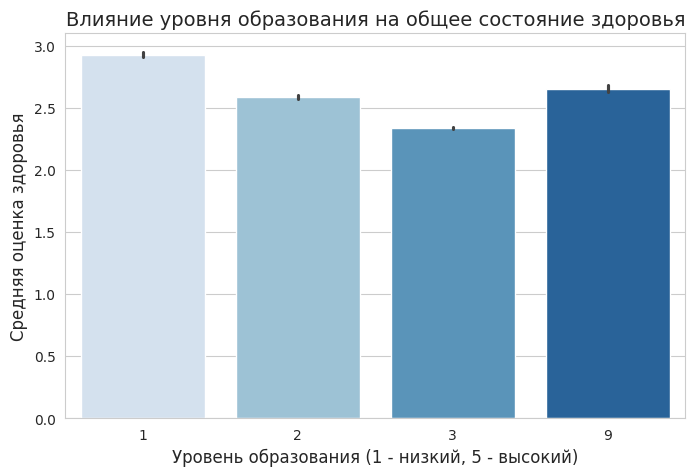
Далее я посмотрела, как уровень образования влияет на общее состояние здоровья у человека.
plt.figure (figsize=(8, 5))
sns.barplot (x=df[«Edu_level»], y=df[«Gen_health_state»], estimator=lambda x: x.mean (), palette="Blues»)
plt.title («Влияние уровня образования на общее состояние здоровья», fontsize=14) plt.xlabel («Уровень образования (1 — низкий, 5 — высокий)», fontsize=12) plt.ylabel («Средняя оценка здоровья», fontsize=12)
plt.show ()
Выяснилось, что люди с более высоким уровнем образования, как правило, оценивают свое здоровье выше.
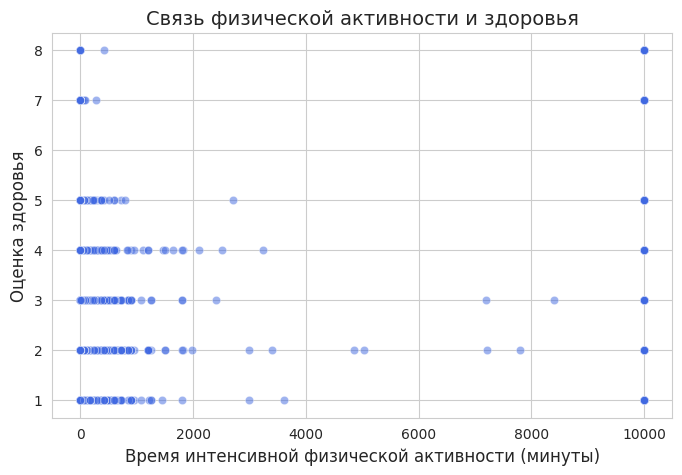
Теперь изучим связь между физической активностью и общим состоянием здоровья.
plt.figure (figsize=(8, 5))
sns.scatterplot (x=df[«Physical_vigorous_act_time»], y=df[«Gen_health_state»], alpha=0.5, color="royalblue»)
plt.title («Связь физической активности и здоровья», fontsize=14) plt.xlabel («Время интенсивной физической активности (минуты)», fontsize=12) plt.ylabel («Оценка здоровья», fontsize=12)
plt.show ()
Диаграмма показала, что люди, занимающиеся более интенсивной физической активностью, чаще имеют более высокие оценки здоровья.
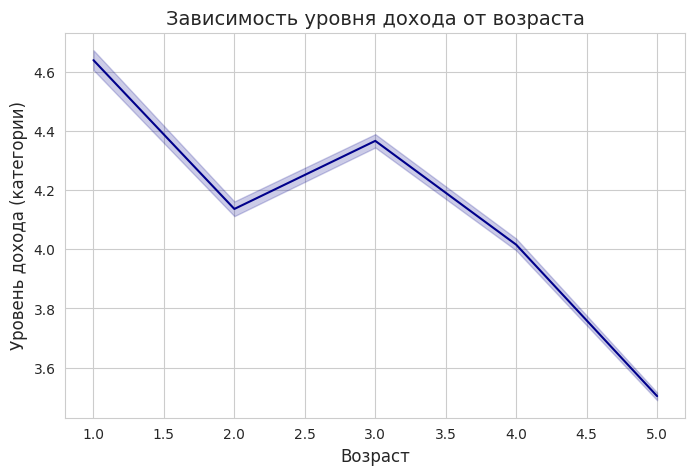
Линейный график показал, что уровень дохода увеличивается с возрастом до определенного момента, а затем начинает снижаться. Это может отражать карьерный рост и выход на пенсию.
plt.figure (figsize=(8, 5))
sns.lineplot (x=df[«Age»], y=df[«Total_income»], color="darkblue»)
plt.title («Зависимость уровня дохода от возраста», fontsize=14) plt.xlabel («Возраст», fontsize=12) plt.ylabel («Уровень дохода (категории)», fontsize=12)
plt.show ()
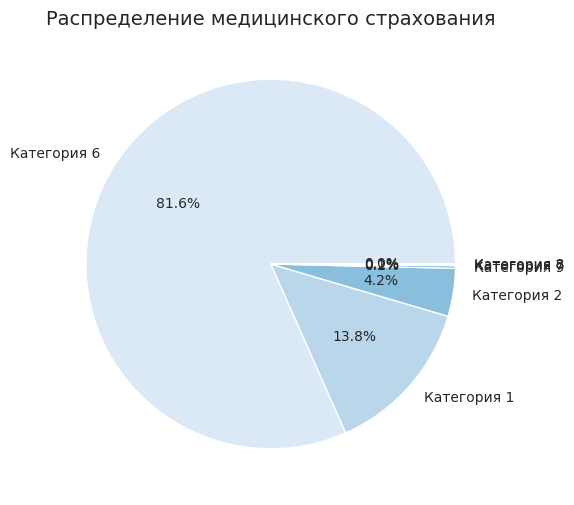
Построим круговую диаграмму, чтобы посмотреть, как распределяется медицинская страховка среди людей.
plt.figure (figsize=(6, 6))
insurance_counts = df[«Insurance_cover»].value_counts () labels = [f"Категория {i}» for i in insurance_counts.index]
plt.pie (insurance_counts, labels=labels, autopct="%1.1f%%», colors=sns.color_palette («Blues», len (insurance_counts)))
plt.title («Распределение медицинского страхования», fontsize=14)
plt.show ()
Большая часть населения имеет страховое покрытие, однако есть исключения.
Итоговые графики
Вывод
Благодаря анализу данных, мы поняли:
- Большинство людей оценивают свое здоровье как хорошее или отличное.
- Состояние здоровья зависит от уровня образование. Чем выше образование, тем здоровье лучше.
- Физическая активность положительно сказывается на уровне здоровья.
- Уровень дохода сначала растет с возрастом, доходит до определенного пика, после снижается.
- Медицинское страхование имеется у большинства.
Описание применения генеративной модели
Для анализа данных использовалась нейросеть https://chatgpt.com



